Are you searching for a solution to the subject “keras model optimizer“? We reply all of your questions on the web site Ar.taphoamini.com in class: See more updated computer knowledge here. You will discover the reply proper beneath.
Keep Reading

Table of Contents
What does keras Optimizer do?
Keras Adagrad optimizer has studying charges that use particular parameters. Based on the frequency of updates acquired by a parameter, the working takes place. Even the educational fee is adjusted in line with the person options. This means there are totally different studying charges for some weights.
How do I optimize keras mannequin?
- Train Keras mannequin to succeed in a suitable accuracy as all the time.
- Make Keras layers or mannequin able to be pruned.
- Create a pruning schedule and prepare the mannequin for extra epochs.
- Export the pruned mannequin by striping pruning wrappers from the mannequin.
[DL] How to decide on an optimizer for a Tensorflow Keras mannequin?
Images associated to the subject[DL] How to decide on an optimizer for a Tensorflow Keras mannequin?
What is Optimizer in mannequin?
An optimization mannequin is a translation of the important thing traits of the enterprise drawback you are attempting to resolve. The mannequin consists of three components: the target operate, determination variables and enterprise constraints.
Which is the very best optimizer for TensorMovement?
Gradient descent vs Adaptive
Adam is your best option usually.
Why do we want Optimizer in deep studying?
While coaching the deep studying mannequin, we have to modify every epoch’s weights and reduce the loss operate. An optimizer is a operate or an algorithm that modifies the attributes of the neural community, corresponding to weights and studying fee. Thus, it helps in decreasing the general loss and enhance the accuracy.
Which optimizer ought to I exploit?
Adam is the very best optimizers. If one desires to coach the neural community in much less time and extra effectively than Adam is the optimizer. For sparse knowledge use the optimizers with dynamic studying fee. If, need to use gradient descent algorithm than min-batch gradient descent is the most suitable choice.
Which Optimizer is finest for CNN?
The Adam optimizer had the very best accuracy of 99.2% in enhancing the CNN capacity in classification and segmentation.
See some extra particulars on the subject keras mannequin optimizer right here:
tf.keras.optimizers.Optimizer | TensorMovement Core v2.9.0
Base class for Keras optimizers. … In Keras fashions, generally variables are created when the mannequin is first known as, as an alternative of development time.
Guide To Tensorflow Keras Optimizers – Analytics India …
Optimizers are Classes or strategies used to vary the attributes of your machine/deep studying mannequin corresponding to weights and studying fee so as …
Keras – Model Compilation – Tutorialspoint
Optimizer. In machine studying, Optimization is a crucial course of which optimize the enter weights by evaluating the prediction and the loss operate. Keras …
Keras optimizers | Kaggle
Adam stands for Adaptive Moment Estimation. In addition to storing an exponentially decaying common of previous squared gradients like Adadelta and RMSprop, Adam …
What is an optimizer in deep studying?
In deep studying, optimizers are used to regulate the parameters for a mannequin. The objective of an optimizer is to regulate mannequin weights to maximise a loss operate. The loss operate is used as a option to measure how effectively the mannequin is performing. An optimizer should be used when coaching a neural community mannequin.
What is Optimizer in TensorMovement?
Optimizers are the prolonged class, which embrace added data to coach a particular mannequin. The optimizer class is initialized with given parameters however it is very important keep in mind that no Tensor is required. The optimizers are used for bettering velocity and efficiency for coaching a particular mannequin.
Why do we want optimization?
The objective of optimization is to attain the “best” design relative to a set of prioritized standards or constraints. These embrace maximizing components corresponding to productiveness, power, reliability, longevity, effectivity, and utilization.
How do you optimize a mannequin?
- Reduce parameter depend with pruning and structured pruning.
- Reduce representational precision with quantization.
- Update the unique mannequin topology to a extra environment friendly one with diminished parameters or quicker execution.
Why Adam is the very best optimizer?
Building upon the strengths of earlier fashions, Adam optimizer provides a lot larger efficiency than the beforehand used and outperforms them by an enormous margin into giving an optimized gradient descent.
134 – What are Optimizers in deep studying? (Keras TensorMovement)
Images associated to the topic134 – What are Optimizers in deep studying? (Keras TensorMovement)
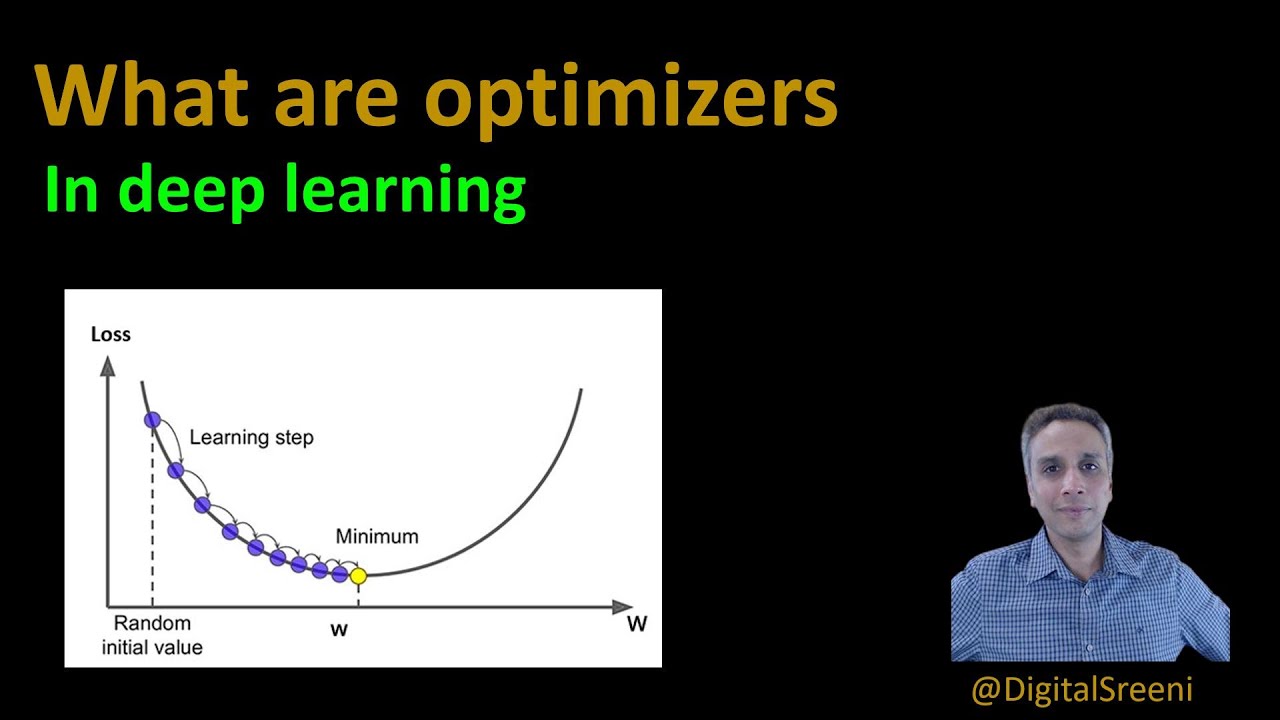
Is Adam higher than AdaGrad?
The studying fee of AdaGrad is ready to be larger than that of gradient descent, however the level that AdaGrad’s path is straighter stays largely true no matter studying fee. This property permits AdaGrad (and different related gradient-squared-based strategies like RMSProp and Adam) to flee a saddle level a lot better.
Is AdamW all the time higher than Adam?
The empirical outcomes present that AdamW can have higher generalization efficiency than Adam (closing the hole to SGD with momentum) and that the basin of optimum hyperparameters is broader for AdamW.
Which Optimizer is finest for regression?
Gradient Descent Optimizer – Regression Made Easy Using TensorMovement. An wonderful instrument for machine studying, gradient descent optimizer can cut back operate by repetitively transferring within the route of descent that’s steepest.
What is Adam Optimizer in keras?
Adam optimization is a stochastic gradient descent technique that’s based mostly on adaptive estimation of first-order and second-order moments.
What is the very best optimization algorithm?
- Gradient Descent. The gradient descent technique is the most well-liked optimisation technique. …
- Stochastic Gradient Descent. …
- Adaptive Learning Rate Method. …
- Conjugate Gradient Method. …
- Derivative-Free Optimisation. …
- Zeroth Order Optimisation. …
- For Meta Learning.
How do you optimize a neural community?
Optimize Neural Networks
Models are skilled by repeatedly exposing the mannequin to examples of enter and output and adjusting the weights to attenuate the error of the mannequin’s output in comparison with the anticipated output. This known as the stochastic gradient descent optimization algorithm.
What is an efficient batch dimension?
Generally batch dimension of 32 or 25 is nice, with epochs = 100 except you’ve gotten giant dataset. in case of enormous dataset you’ll be able to go along with batch dimension of 10 with epochs b/w 50 to 100.
Which Optimizer is finest for NLP?
Optimization algorithm Adam (Kingma & Ba, 2015) is among the hottest and broadly used optimization algorithms and infrequently the go-to optimizer for NLP researchers. It is usually thought that Adam clearly outperforms vanilla stochastic gradient descent (SGD).
Is SGD higher than Adam?
By evaluation, we discover that in contrast with ADAM, SGD is extra regionally unstable and is extra more likely to converge to the minima on the flat or uneven basins/valleys which regularly have higher generalization efficiency over different sort minima. So our outcomes can clarify the higher generalization efficiency of SGD over ADAM.
What is the Adam optimizer used for?
Adam is a alternative optimization algorithm for stochastic gradient descent for coaching deep studying fashions. Adam combines the very best properties of the AdaGrad and RMSProp algorithms to offer an optimization algorithm that may deal with sparse gradients on noisy issues.
Optimizers, Loss Functions and Learning Rate in Neural Networks with Keras and TensorMovement
Images associated to the subjectOptimizers, Loss Functions and Learning Rate in Neural Networks with Keras and TensorMovement

Why is ReLu most popular over sigmoid?
Efficiency: ReLu is quicker to compute than the sigmoid operate, and its by-product is quicker to compute. This makes a big distinction to coaching and inference time for neural networks: solely a relentless issue, however constants can matter. Simplicity: ReLu is easy.
Does Adam Optimizer change studying fee?
Although particulars about this optimizer are past the scope of this text, it is value mentioning that Adam updates a studying fee individually for every mannequin parameter/weight. This implies that with Adam, the educational fee could first improve at early layers, and thus assist enhance the effectivity of deep neural networks.
Related searches to keras mannequin optimizer
- keras get mannequin optimizer
- rmsprop optimizer
- keras mannequin.optimizer.lr
- keras mannequin save optimizer state
- tensorflow keras mannequin optimizer
- tensorflow optimizers
- openvino mannequin optimizer keras
- sgd optimizer
- keras load mannequin optimizer
- from keras optimizers import adam
- keras mannequin.optimizer.lr.get_value()
- keras optimizers adam not discovered
- module keras optimizers has no attribute sgd
- keras save mannequin with out optimizer
- keras adam optimizer
- from keras.optimizers import adam
- keras sequential mannequin optimizer
- mannequin.compile keras
- mannequin compile keras
- keras mannequin change optimizer
- keras mannequin set optimizer
- keras mannequin get optimizer
Information associated to the subject keras mannequin optimizer
Here are the search outcomes of the thread keras mannequin optimizer from Bing. You can learn extra if you need.
You have simply come throughout an article on the subject keras model optimizer. If you discovered this text helpful, please share it. Thank you very a lot.